 Illustration
Illustration
摘要
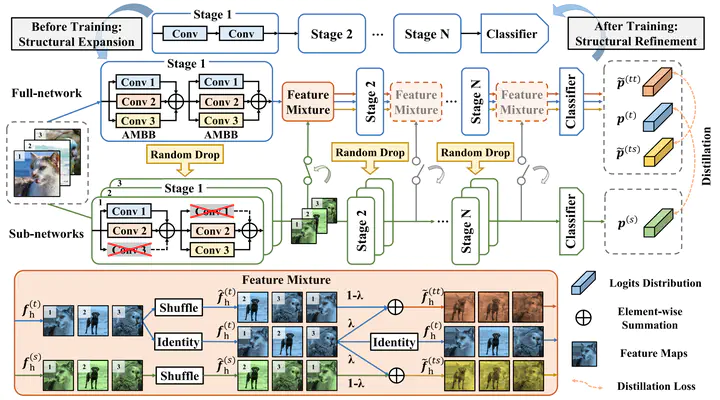
Knowledge distillation aims to achieve model compression by transferring knowledge from complex teacher models to lightweight student models. To reduce reliance on pre-trained teacher models, self-distillation methods utilize knowledge from the model itself as additional supervision. However, their performance is limited by the same or similar network architecture between the teacher and student. In order to increase architecture variety, we propose a new self-distillation framework called restructured self-distillation (RSD), which involves restructuring both the teacher and student networks. The self-distilled model is expanded into a multi-branch topology to create a more powerful teacher. During training, diverse student sub-networks are generated by randomly discarding the teacher’s branches. Additionally, the teacher and student models are linked by a randomly inserted feature mixture block, introducing additional knowledge distillation in the mixed feature space. To avoid extra inference costs, the branches of the teacher model are then converted back to its original structure equivalently. Comprehensive experiments have demonstrated the effectiveness of our proposed framework for most architectures on CIFAR-10/100 and ImageNet datasets. Code is available at https://github.com/YujieZheng99/RSD.